3 Buyer Groupings
3.1 Buyer Information Fields
Buyers will be considered at the tender level (i.e., one buyer for each row in the llamado table). The tables containing buyer/entity information are:
unidad_contratacion- left join onto pac by
pac.unidad_contratacion_id = unidad_contratacion.id - variable of interest:
descripcion(description of the buyer; probably easiest to do text mining on, since it includes exact institution names like “hospital” or “university”) - additional variables:
tipo(UOC, SUOC, or UEP) andinstitucion(whether the buyer is an institution or not)
- left join onto pac by
entidad- left join onto
unidad_contratacionbyunidad_contratacion.entidad_codigo_sicp = entidad.codigo_sicp - NOTE:
entidadhas multiple rows for each value ofentidad.codigo_sicp(one per year), so the left join must be performed using a reduced version ofentidadwith a single row for each value (see the code snippet below for implementation) - variable of interest:
nombre(name of the buyer at a higher level; does not include specific institution names, only broad government and municipality information)
- left join onto
nivel_entidad- left join onto
entidadby(entidad.anio, entidad.nivel_entidad_codigo) = (nivel_entidad.anio, nivel_entidad.nivel_entidad_codigo) - variable of interest:
nombre(very broad buyer levels within the public sector)
- left join onto
CONCLUSIONS: Combine unidad_contratacion.nombre and entidad.nombre into a single string to perform text mining on. Since nivel_entidad.nombre has relatively few categories with little text, it does not lend itself well to text mining. Instead, experiment with it as a categorical variable in its own right.
3.2 Adding Buyer Information to Tenders
ISSUE: The buyer joining process must somehow be incorporated into the feature engineering script, but relational column inconsistencies (in terms of naming and number) and the bidirectional joining order would significantly increase the complexity of the config file.
IMPLEMENTED SOLUTION: Perform the buyer joining process in a separate script, which then gets sourced within the feature engineering script if buyer-related variables are listed as predictors in the config file.
3.3 Buyer Levels
We fit an OLS regression model for log_precio_unitario (our target) against nivel_entidad to see how much variability this predictor accounts for by itself.
| F(14,3282352) | 3566.7951 |
| R² | 0.0150 |
| Adj. R² | 0.0150 |
| Est. | S.E. | t val. | p | |
|---|---|---|---|---|
| (Intercept) | 12.4913 | 0.0184 | 678.0445 | 0.0000 |
| nivel_entidadcapacitacion dncp | -4.4322 | 1.9485 | -2.2747 | 0.0229 |
| nivel_entidadcontraloria general de la republica | -1.0160 | 0.0419 | -24.2320 | 0.0000 |
| nivel_entidaddefensoria del pueblo | -1.5444 | 0.0648 | -23.8431 | 0.0000 |
| nivel_entidadempresas mixtas | 0.3968 | 0.0224 | 17.6902 | 0.0000 |
| nivel_entidadempresas publicas | -0.3827 | 0.0193 | -19.7782 | 0.0000 |
| nivel_entidadentes autonomos y autarquicos | -0.3336 | 0.0195 | -17.0953 | 0.0000 |
| nivel_entidadentidades financieras oficiales | -0.3138 | 0.0212 | -14.8353 | 0.0000 |
| nivel_entidadentidades publicas de seguridad social | -0.2579 | 0.0202 | -12.7640 | 0.0000 |
| nivel_entidadgobiernos departamentales | -0.2731 | 0.0193 | -14.1613 | 0.0000 |
| nivel_entidadmunicipalidades | -0.5206 | 0.0188 | -27.6727 | 0.0000 |
| nivel_entidadpoder ejecutivo | -0.9751 | 0.0186 | -52.4557 | 0.0000 |
| nivel_entidadpoder judicial | -0.4177 | 0.0192 | -21.7252 | 0.0000 |
| nivel_entidadpoder legislativo | -0.3389 | 0.0218 | -15.5240 | 0.0000 |
| nivel_entidaduniversidades nacionales | -1.1089 | 0.0190 | -58.2084 | 0.0000 |
| Standard errors: OLS |
By itself, nivel_entidad accounts for a statistically significant 1.5% of the variability in log_precio_unitario, so we might consider including it in our model. But what about in conjunction with other predictors?
ISSUE: The nivel_entidad variable has 15 categories; we must find the best way to merge them.
3.4 Buyer Names and Descriptions
We join the name and description of a buyer into a single string for each tender and perform text mining.
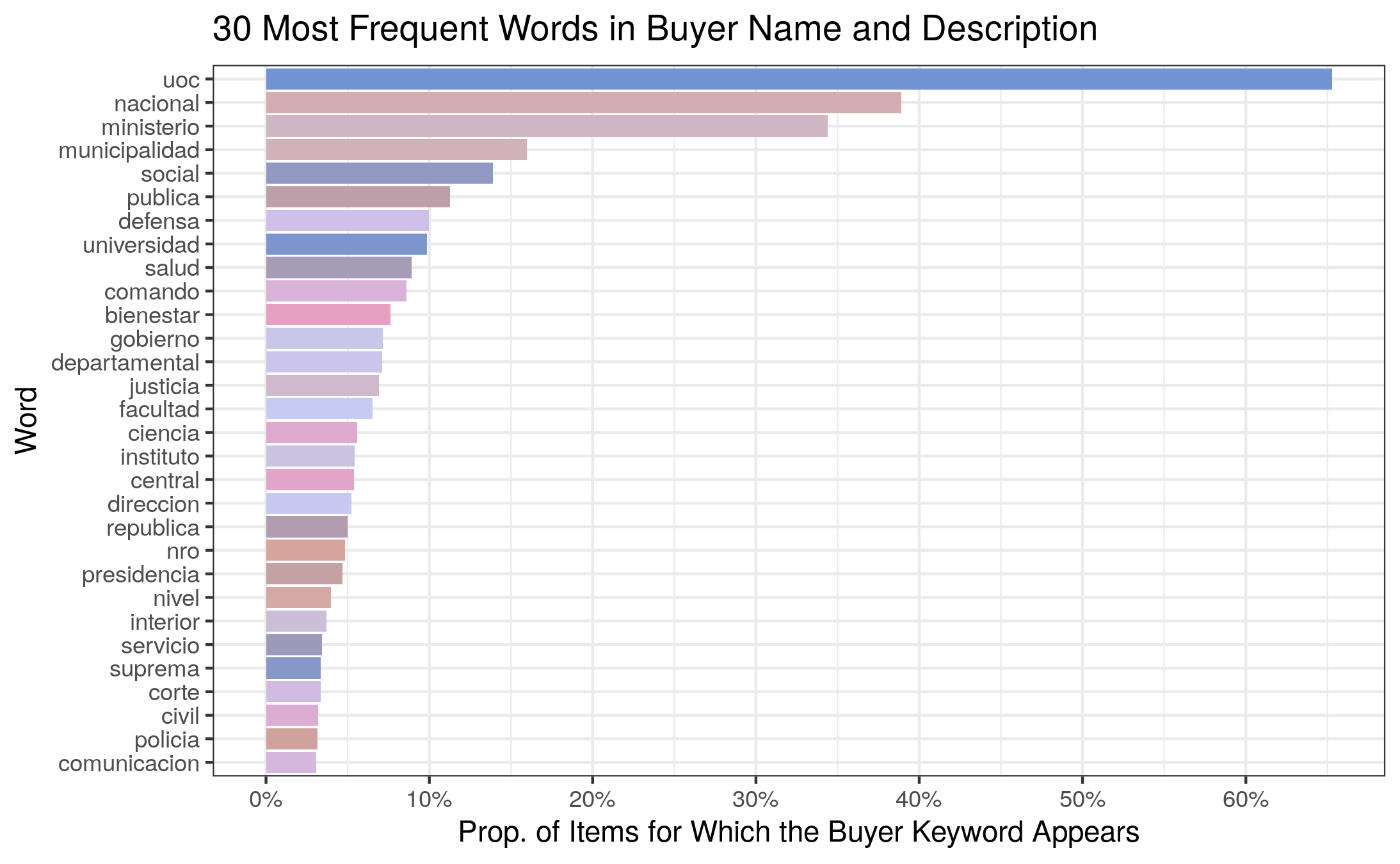
3.5 Most Frequent Words
Below are the 30 most frequent words in the buyer descriptions, along with the proportion of items for which that buyer keyword appears:
3.6 Final Buyer Groupings
Since there may be overlap between the keywords present in each buyer name and description, we will be treating the buyer groupings as indicator variables (to which a buyer either belongs or not) – mutually exclusive categories would not make sense here. Some potential indicator variable groupings are:
- Police:
"policia" - Hospital:
"hospital"or"cancer" - Science:
"ciencia" - Health:
"salud" - Law:
"justicia"or"judicial" - Ministry:
"ministerio" - Education:
"universidad","facultad", or"educacion" - Army:
"defensa","comando","armada", or"ejercito" - Bank:
"banco" - Tech:
"tecnologia"or"aeronautica" - Electricity:
"ande"(administracion nacional de electricidad) or"electricidad"
| Grouping | String Pattern | Proportion |
|---|---|---|
| police | policia | 3.15% |
| hospital | hospital|cancer | 1.60% |
| science | ciencia | 5.82% |
| health | salud | 8.95% |
| law | justicia|judicial | 7.11% |
| ministry | ministerio | 34.52% |
| education | universidad|facultad|educacion | 10.95% |
| army | defensa|comando|armada|ejercito | 10.01% |
| bank | banco | 1.94% |
| tech | tecnologia|aeronautica | 3.39% |
| electricity | ande|electricidad | 2.49% |
3.7 Variable Importance Exploration
Finally, we explore the importance of the above groupings when it comes to explaining the variability in log_precio_unitario. To find out which indicators might be worth keeping in the baseline regression model, we perform variable selection using the best subsets method. The importance of the different indicators might change once we include other variables, but this is a good first look at what might be most important.
| 10 Vars | 9 Vars | 8 Vars | 7 Vars | 6 Vars | 5 Vars | 4 Vars | 3 Vars | 2 Vars | 1 Vars | |
|---|---|---|---|---|---|---|---|---|---|---|
| Adjr2 | 0.0246 | 0.0246 | 0.0244 | 0.0242 | 0.0236 | 0.0229 | 0.0220 | 0.0199 | 0.0157 | 0.0112 |
| Cp | 183.53 | 366.21 | 828.40 | 1574.61 | 3689.67 | 5891.46 | 8936.16 | 16108.72 | 30183.28 | 45445.77 |
| Bic | -81.63k | -81.46k | -81.01k | -80.28k | -78.18k | -75.99k | -72.97k | -65.84k | -51.87k | -36.8k |
| Police |
|
|
|
|
|
|
|
|||
| Hospital |
|
|
|
|
|
|
||||
| Science | ||||||||||
| Health |
|
|
|
|
|
|
|
|
|
|
| Law |
|
|
|
|
|
|||||
| Ministry |
|
|
||||||||
| Education |
|
|
|
|
|
|
|
|
||
| Army |
|
|
|
|
|
|
|
|
|
|
| Bank |
|
|||||||||
| Tech |
|
|
|
|||||||
| Electricity |
|
|
|
|
3.8 Implementation Conclusions
A total of 11 buyer indicator variables (listed above) were created based on the cleaned-up and merged buyer descriptions. Each indicator variable corresponds to certain specific string patterns, and the variable will be TRUE for a particular observation if that observation’s clean buyer description matches those patterns. Otherwise, the indicator variable will be FALSE.